- Институт
- Зертханалар
- Ғылым
- Іс-шаралар
- Журнал
- Жаңалықтар
- Байланысу
- Кері байланыс
Қазақ-орыс ым тілін жазбаша мәтінге және керісінше аудару, сондай-ақ ауызша сөйлеуді ишаралар мен мәтінге түрлендіру арқылы саңырау, нашар еститін және еститін адамдар арасындағы коммуникацияны жеңілдететін жүйені құру әртүрлі деңгейдегі есту қабілеті бар адамдар үшін ақпарат пен қарым-қатынастың қолжетімділігін айтарлықтай жақсарта алады.
Есту және сөйлеу қабілеті шектеулі адамдар қарым-қатынас жасау үшін ым тілін қолданады, алайда оны олардың еститін сұхбаттастары әрдайым түсіне бермейді. Ым тілін меңгеру, вербалды тіл сияқты, есту және сөйлеу қабілеті шектеулі адамның тұлға болып қалыптасуында, оның психикалық дамуында және әлеуметтенуінде маңызды рөл атқарады. Есту және сөйлеу қабілеті шектеулі адамдарға арналған жасанды интеллектіні пайдалану арқылы сурдо-ресурстар кешенін әзірлеу – қазіргі қоғам алдында тұрған ең маңызды міндеттердің бірі болып табылады. Ым тілін аудару мен интерпретациялауға арналған тиімді құралдардың жетіспеушілігіне байланысты есту және сөйлеу қабілеті шектеулі адамдардың білім алуда, жұмысқа орналасуда және әлеуметтік интеграцияда мүмкіндіктері шектеулі.
Қазақ-орыс ым тілі (ҚОЫТ) – Қазақстан аумағында тұратын есту қабілеті шектеулі адамдардың қарым-қатынас жасау үшін қолданатын табиғи тілі болып табылады. Негізгі жетістіктердің бірі – қазақ тіліндегі мәтіндерді өңдеуге арналған лексико-морфологиялық талдау (ЛМТ) блогын әзірлеу болды. Осы орта аясында мультимедиялық тезаурустар жасалып, кеңейтілді, ым тілі тезаурус-сөздігінің деректер қоры қалыптастырылды және дактильді анимациялық модельдерді құруға арналған бағдарламалар әзірленді.
Сонымен қатар, күнделікті қарым-қатынаста қолданылатын ишараларды жүйелеу және стандарттау мүмкіндігін берген ишара тілі корпусын қалыптастыру жұмыстары жүргізілді. Сөздерді автоматты түрде ишараларға аударуға арналған бағдарламалық прототиптер әзірленді және ишаралардың бейнежазбаларын, дактильдік модельдерді және мәтіндік сипаттамаларды қамтитын мультимедиялық материалдардың деректер қоры жасалды. Бұл нәтижелер есту қабілеті шектеулі адамдар мен еститін пайдаланушылар арасындағы инклюзивті коммуникацияны қамтамасыз ете алатын зияткерлік жүйелерді құрудың негізін қалады.
Сурет 1 – Машиналық оқыту және терең оқыту модельдері
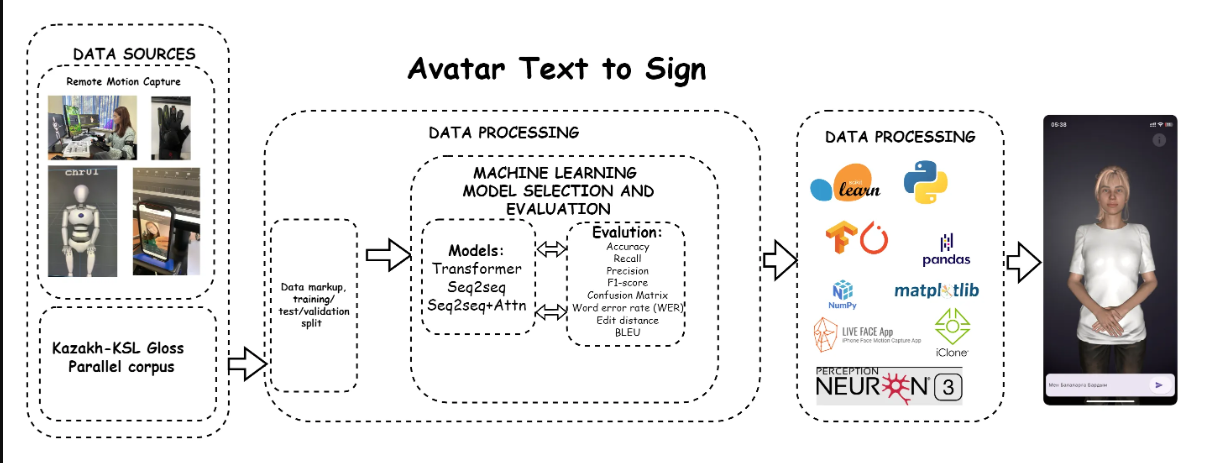
Процесс деректер көздерінен басталады, оған қашықтан қимылды түсіру (Remote Motion Capture) және қазақ тілі мен қазақ ым тілі глосс параллель корпусын (Kazakh-KSL Gloss Parallel corpus) қамтиды. Бұл деректер белгілеу кезеңінен өтіп, оқыту, тестілеу және валидациялық жиынтықтарға бөлінеді.
Деректерді өңдеу кезеңінде машиналық оқыту модельдерін таңдау және бағалау жүзеге асырылады. Transformer, Seq2Seq және назар механизмі бар Seq2Seq (Seq2Seq+Attn) сияқты модельдер қарастырылады. Бұл модельдердің тиімділігін бағалау үшін дәлдік (Accuracy), толықтық (Recall), нақтылық (Precision), F1-score, қателік матрицасы (Confusion Matrix), сөз қателері (WER), редакциялық қашықтық (Edit distance) және BLEU метрикалары қолданылды.
Келесі деректерді постөңдеу кезеңінде scikit-learn, Python, TensorFlow, PyTorch, pandas, NumPy, matplotlib, LIVE FACE App, iClone және Perception Neuron 3 сияқты әртүрлі кітапханалар мен құралдар қолданылады. Бұл құралдар деректерді талдауға және визуализациялауға, сондай-ақ аватарға арналған анимациялар жасауға көмектеседі.
Қорытынды нәтиже – енгізілген мәтінге сәйкес ишараларды орындайтын аватарды визуализациялау, бұл мәтінді ым тіліне нақты уақыт режимінде аударуға мүмкіндік береді. Бұл процесс заманауи технологиялар мен машиналық оқыту әдістерінің интеграциясын көрсетіп, адамдар мен машиналар арасындағы коммуникацияны жақсартуға, әсіресе есту және сөйлеу қабілеті шектеулі адамдарды қолдау контекстінде ықпал етеді.
Шетелдік басылымдар:
Отандық басылымдар: