Cоздание системы, которая облегчит коммуникацию между глухими, слабослышащими и слышащими людьми через перевод казахско-русского жестового языка в письменный текст и обратно, а также через преобразование устной речи в жесты и текст, может значительно улучшить доступность информации и общения для людей с различными уровнями слуховой функции.
Люди с нарушениями слуха и речи для общения используют жестовый язык, который не всегда понимают их слышащие собеседники. Владение жестовым языком, также как и вербальным, играет важную роль в формировании личности человека с нарушением слуха и речи, его психическом развитии и социализации. Разработка комплекса сурдо-ресурсов с использованием искусственного интеллекта для людей с нарушением слуха и речи является одной из важнейших задач, стоящих перед современным обществом. Вследствие нехватки эффективных инструментов для перевода и интерпретации жестового языка, возможности людей с нарушением слуха и речи в образовании, трудоустройстве и социальной интеграции ограничены.
Казахско-русский жестовый язык (КРЖЯ) является естественным языком, используемым для коммуникации людьми с нарушениями слуха, проживающими на территории Казахстана. Одним из ключевых достижений стала разработка блока лексико-морфологического анализа (ЛМА) для обработки текстов на казахском языке. В рамках этой среды были созданы и расширены мультимедийные тезаурусы, сформирована база данных жестового словаря-тезауруса и разработаны программы для создания дактильных анимационных моделей.
Кроме того, проведена работа по формированию корпуса жестового языка, что позволило систематизировать и стандартизировать жесты, используемые в повседневной коммуникации. Были разработаны программные прототипы для автоматического перевода слов в жесты и создана база данных мультимедийных материалов, включающая видеозаписи жестов, дактильные модели и текстовые описания. Эти результаты легли в основу создания интеллектуальных систем, способных обеспечивать инклюзивную коммуникацию между людьми с нарушениями слуха и слышащими пользователями.
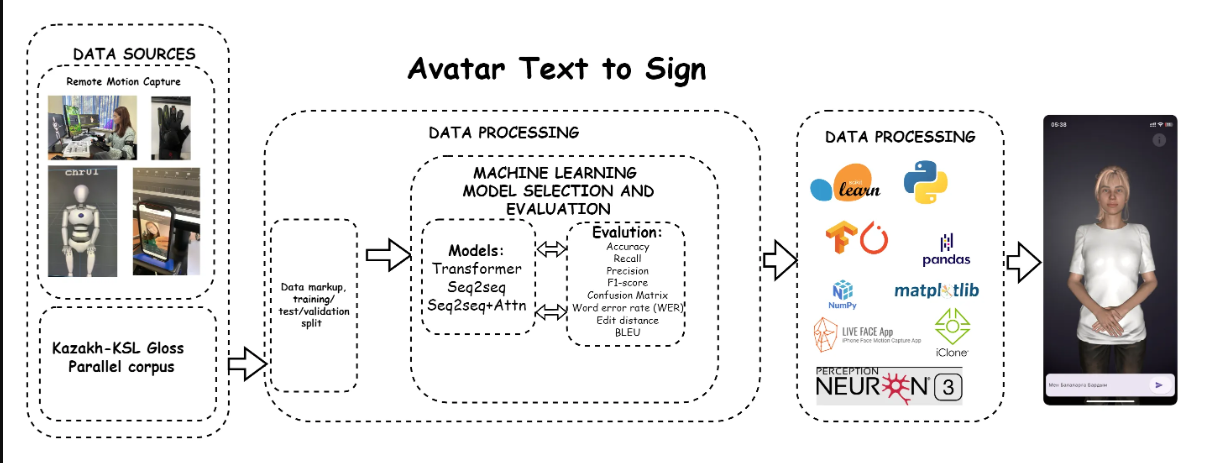
Рисунок 1 – Модели машинного обучения и глубокого обучения
Процесс начинается с источников данных, которые включают удалённый захват движений (Remote Motion Capture) и параллельный корпус глосс на казахском и казахском жестовом языке (Kazakh-KSL Gloss Parallel corpus). Эти данные проходят этап разметки и разделения на обучающую, тестовую и валидационную выборки.
На этапе обработки данных осуществляется выбор и оценка моделей машинного обучения. Рассматриваются модели, такие как Transformer, Seq2Seq и Seq2Seq с вниманием (Seq2Seq+Attn). Для оценки эффективности этих моделей используются метрики точности (Accuracy), полноты (Recall), точности (Precision), F1-score, матрицы ошибок (Confusion Matrix), ошибки слов (WER), редакционного расстояния (Edit distance) и BLEU.
На следующем этапе постобработки данных применяются различные библиотеки и инструменты, включая scikit-learn, Python, TensorFlow, PyTorch, pandas, NumPy, matplotlib, LIVE FACE App, iClone и Perception Neuron 3. Эти инструменты помогают анализировать и визуализировать данные, а также создавать анимации для аватара .
Конечным результатом является визуализация аватара, выполняющего жесты в соответствии с введенным текстом, что позволяет осуществлять перевод текста на жестовый язык в реальном времени. Этот процесс демонстрирует интеграцию современных технологий и методов машинного обучения для улучшения коммуникации между людьми и машинами, особенно в контексте поддержки людей с нарушениями слуха и речи.