- Home
- Institute
- Laboratories
- Science
- Events
- Journal
- News
- Contact
- Feedback
Creating a system facilitating communication between deaf, hard of hearing and hearing people via translation of Kazakh-Russian sign language into written text and vice versa, and through spoken language conversion into gestures and text, will improve the information and communication access for people with multilevel hearing functions.
People with hearing and speech impairments use sign language to communicate, but their hearing interlocutors do not always understand it. Mastery of sign language, just like verbal language, plays an important role in the formation of the personality of a person with hearing and speech impairments, as well as in their psychological development and socialization. The development of a set of surdo-resources using artificial intelligence for people with hearing and speech impairments is one of the most important tasks facing modern society. Due to the lack of effective tools for translating and interpreting sign language, the opportunities of people with hearing and speech impairments in education, employment, and social integration are limited.
Kazakh-Russian Sign Language (KRSL) is a natural language used for communication by people with hearing impairments living in Kazakhstan. One of the key achievements was the development of a lexico-morphological analysis (LMA) module for processing texts in the Kazakh language. Within this framework, multimedia thesauri were created and expanded, a database of a sign language thesaurus dictionary was formed, and software for generating dactyl animation models was developed.
In addition, work has been carried out to create a sign language corpus, which made it possible to systematize and standardize the signs used in everyday communication. Software prototypes for automatic translation of words into signs were developed, and a database of multimedia materials was created, including video recordings of signs, dactyl models, and textual descriptions. These results formed the basis for the development of intelligent systems capable of providing inclusive communication between people with hearing impairments and hearing users.
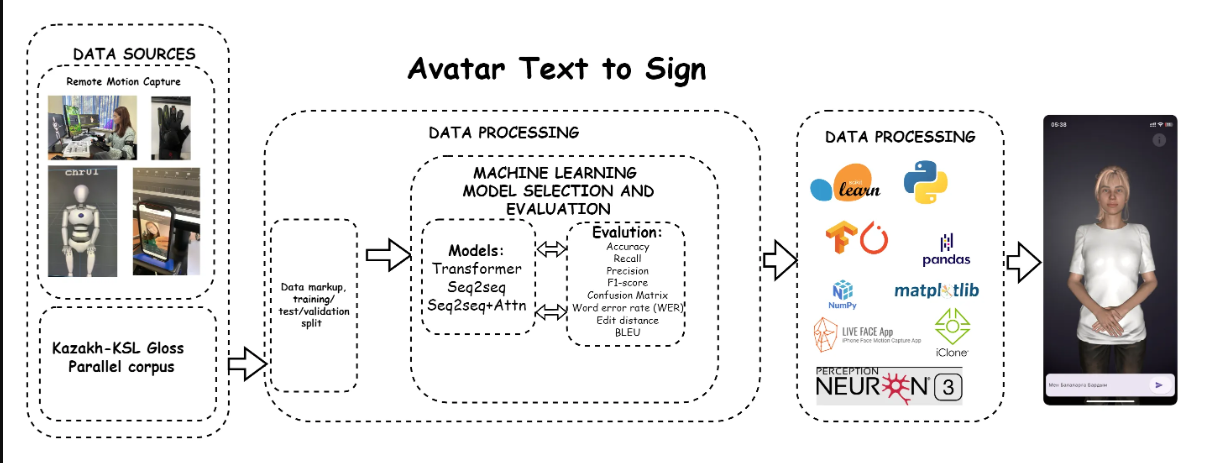
Figure 1 – Machine learning and deep learning models
The process begins with data sources, which include Remote Motion Capture and the Kazakh-KSL Gloss Parallel Corpus. These data go through the stages of annotation and splitting into training, testing, and validation sets.
At the data processing stage, machine learning models are selected and evaluated. Models such as Transformer, Seq2Seq, and Seq2Seq with Attention (Seq2Seq+Attn) are considered. To assess the effectiveness of these models, evaluation metrics such as Accuracy, Recall, Precision, F1-score, Confusion Matrix, Word Error Rate (WER), Edit Distance, and BLEU are used.
At the next stage of data post-processing, various libraries and tools are used, including scikit-learn, Python, TensorFlow, PyTorch, pandas, NumPy, matplotlib, LIVE FACE App, iClone, and Perception Neuron 3. These tools help analyze and visualize data, as well as create animations for the avatar.
The final result is the visualization of an avatar performing gestures according to the input text, enabling real-time translation of text into sign language. This process demonstrates the integration of modern technologies and machine learning methods to enhance communication between humans and machines, particularly in the context of supporting people with hearing and speech impairments.
Foreign publications:
Domestic publications: